


What is Chunking in LLMs?
Part of "LLM 101" Series

We learned how the input data are tokenized and embedded in the previous “LLM 101” posts.
What Are Tokens & Parameters in Large Language Models?
Understanding Embeddings in LLMs
Chunking is another step in text preparation for the models.
Chunking is a fundamental technique in AI, especially when dealing with large volumes of data, particularly text.
What is Chunking?
Chunking is a preprocessing step that transforms raw, often unstructured data (like long documents, audio streams, or video feeds) into discrete, manageable units. This process is particularly vital in systems that rely on efficient information retrieval and contextual understanding, such as Retrieval-Augmented Generation (RAG) systems.
Why Do Models Need Chunking?
Most AI models, like GPT, have a limit on how much data they can read at once. This limit is usually based on tokens, not words (1 word ~= 1.3 tokens). So, if your input is too long, it gets cut off or even ignored.
These limitations are often related to their “context window” or “memory”
Context Window Limitations: Large Language Models (LLMs) have a finite context window, meaning they can only process a limited number of tokens (words or sub-word units) at a time. Chunking ensures that the input fits within this window, preventing truncation of important information.
Improved Relevance: By breaking down data into semantically coherent chunks, the system can retrieve more relevant information for a given query. If a chunk contains too much unrelated information, it can dilute the relevance score during retrieval, leading to less accurate responses.
Computational Efficiency: Smaller chunks reduce the computational load during embedding generation, similarity searches, and subsequent processing by the LLM. This leads to faster inference times and lower resource consumption.
Reduced Hallucinations: In RAG systems, well-defined chunks help ground the LLM’s responses in factual, retrieved information, thereby minimizing the generation of incorrect or fabricated content.
The Chunking Process
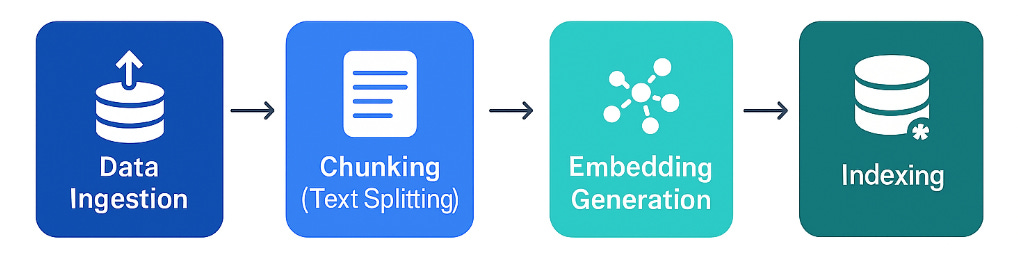
Data Ingestion: Raw data is fed into the chunking pipeline.
Text Splitting (for text data): This is the core of chunking. Various algorithms and strategies are employed to divide the text based on different criteria.
Text Splitting = Chunking + Tokenization
Embedding Generation: Each chunk is then converted into a numerical representation called an embedding using an embedding model. These embeddings capture the semantic meaning of the chunk.
Indexing: The embeddings are stored in a vector database, enabling fast and efficient similarity searches.
Chunking Strategies

The choice of chunking strategy significantly impacts the performance of models, especially in retrieval-based systems. Also, depends heavily on the specific application, the nature of the data. Different techniques offer various trade-offs between precision, coherence, and computational cost. Here are some common types:
1. Rule-Based Chunking
Rule-based chunking relies on predefined rules to split the data. These methods are generally straightforward to implement and computationally inexpensive.
Character-Level Chunking (e.g., CharacterTextSplitter)
Recursive Character Text Splitting (e.g., RecursiveCharacterTextSplitter)
Fixed-Size Chunking
Delimiter-Based Chunking
Disadvantages: The main downside of this chunking strategy is that it just cuts text based on length or delimiter, without really understanding the meaning. So, it might break up sentences or in ways that feel unnatural or confusing.
2. Semantic Chunking
Semantic chunking focuses on grouping text based on its meaning rather than just arbitrary length or structural rules. This approach aims to ensure that each chunk represents a coherent and complete. It preserves the meaning and relevance of information, making it ideal for retrieval tasks that demand high precision and contextual understanding.
This technique uses embeddings or similarity scores derived from language models to identify where natural breaks in meaning occur. Text segments with high semantic similarity are grouped together.
Disadvantages: Computationally more intensive during preprocessing, especially for large datasets, as it requires generating embeddings and performing similarity calculations.
3. LLM-Based Chunking
LLM-based chunking leverages the intelligence of Large Language Models themselves to segment text. This is the most advanced and flexible approach. Highly accurate and tailored for specialized domains. Can understand complex relationships.
Disadvantages: Resource-intensive with higher upfront costs for computation and implementation due to the need to run an LLM for chunking.
4. Others
Overlap Chunking
Hierarchical Chunking
Metadata-Based Chunking
~ Code
There are several popular libraries that support text chunking, such as LangChain, tiktoken, and nltk, or you can build your own custom chunking logic.
Below is an example using RecursiveCharacterTextSplitter from LangChain to split a long text into overlapping chunks.

Learn More…
https://www.pinecone.io/learn/chunking-strategies/
https://cohere.com/blog/chunking-for-rag-maximize-enterprise-knowledge-retrieval