


Understanding Embeddings in LLMs
Part of "LLM 101" Series

Follow-up from last post: "What are tokens & parameters in AI models?" If you haven’t checked it out yet, take a look. it adds useful background to understand embeddings topic.
Embeddings in Simple Terms?
Imagine words are people trying to attend a party. The problem is, the security system at the door only understands numbers, not text. So, to let them in, each word needs a special numerical ID that carries meaning about who they are.
That’s what embeddings do: they turn words (or sentences, or data) into numerical representations called vectors (lists of numbers) that capture their meaning and context in a high-dimensional space.
Technically Speaking...
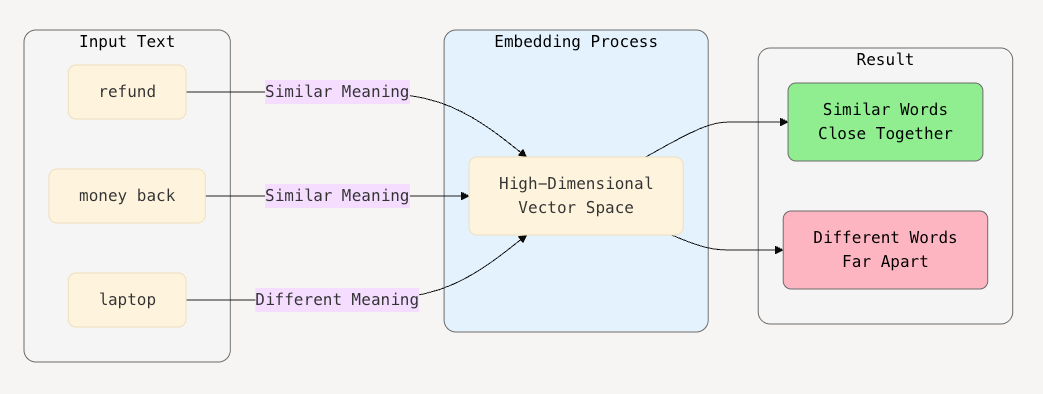
For example, words like "refund" and "money back" would be placed close together in this numerical space, while unrelated words like "laptop" would be farther away.
An embedding is a dense vector of numbers (e.g., [0.12, -0.98, 0.53, ...]) representing a word or a piece of text in a high-dimensional space (like 768 or 1536 dimensions in real models).
Why 768 or 1536 specifically?
The numbers like 768 or 1536 refer to the dimensionality of the embedding vectors. Basically, how many numbers are used to represent a word, sentence, or input. These aren't random; they're architecture-specific choices made when designing language models. If a model has 768-dimensional embeddings, that means each token is represented as a vector of 768 numbers.
768: This is the hidden size (i.e., the dimensionality of embeddings) in models like BERT-base.
1536: This is used by OpenAI's
text-embedding-ada-002model, which generates 1536-dimensional vectors for inputs.

Because real-world language is complex and nuanced. A single number or 2D coordinate isn’t enough to capture the relationships. In embedding space, these relationships become geometric patterns.
Embedding Vectors (Example)
Let’s take the word "money" and “refund”, and the model gives this embedding in 768-dimensional vector.
# example values
"money" → [0.32, -0.19, 0.87, ..., 0.05]
"refund" → [0.30, -0.20, 0.85, ..., 0.06]Notice they're numerically close, which means the model understands that these words are semantically similar.
Why Embeddings Matter in LLMs & Where They Fit in the Workflow
Without embeddings, LLMs would only see arbitrary word IDs (like "apple" = 1021, "banana" = 573), no context or similarity. There would be no way to capture relationships, meaning, or intent.
Right after Tokenization, and before Transformer processing.

Pre-trained Embedding Models
Why Do We Need Pre-Trained Embedding Models?
Because training embeddings from scratch is hard, slow, and requires a lot of data but language understanding is universal, so we can reuse it. When we use a pre-trained embedding model, we're using a map of language that someone already built by reading millions of documents.

Embeddings Used in
Semantic Search: Find similar documents or questions
Recommendations: Match users to products based on text
Clustering: Group similar content
LLM Memory: For retrieval-augmented generation (RAG)
Additional Reads : https://huggingface.co/spaces/hesamation/primer-llm-embedding